GPT-3: A new step towards general Artificial Intelligence

GPT-3: A new step towards general Artificial Intelligence
What is Machine Learning?
Machine learning is an application of artificial intelligence (AI) that provides systems with the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
The process of learning begins with observations or data, such as examples, direct experience, or instruction, in order to look for patterns in data and make better decisions in the future based on the examples that we provide. The primary aim is to allow the computers to learn automatically without human intervention or assistance and adjust actions accordingly.
What Is Artificial Intelligence (AI)?
Artificial intelligence (AI) refers to the simulation of human intelligence in machines that are programmed to think like humans and mimic their actions. The term may also be applied to any machine that exhibits traits associated with a human mind such as learning and problem-solving. The ideal characteristic of artificial intelligence is its ability to rationalize and take actions that have the best chance of achieving a specific goal.
In recent years, the AI circus really has come to town and we’ve been treated to a veritable parade of technical aberrations seeking to dazzle us with their human-like intelligence. Many of these sideshows have been “embodied” AI, where the physical form usually functions as a cunning disguise for a clunky, pre-programmed bot. Like the world’s first “AI anchor,” launched by a Chinese TV network and how could we ever forget Sophia, Saudi Arabia’s first robotic citizen.
Artificial intelligence is based on the principle that human intelligence can be defined in a way that a machine can easily mimic it and execute tasks, from the most simple to those that are even more complex. The goals of artificial intelligence include learning, reasoning, and perception. AI is continuously evolving to benefit many different industries. Machines are wired using a cross-disciplinary approach based in mathematics, computer science, linguistics, psychology, and more.
GPT — 3
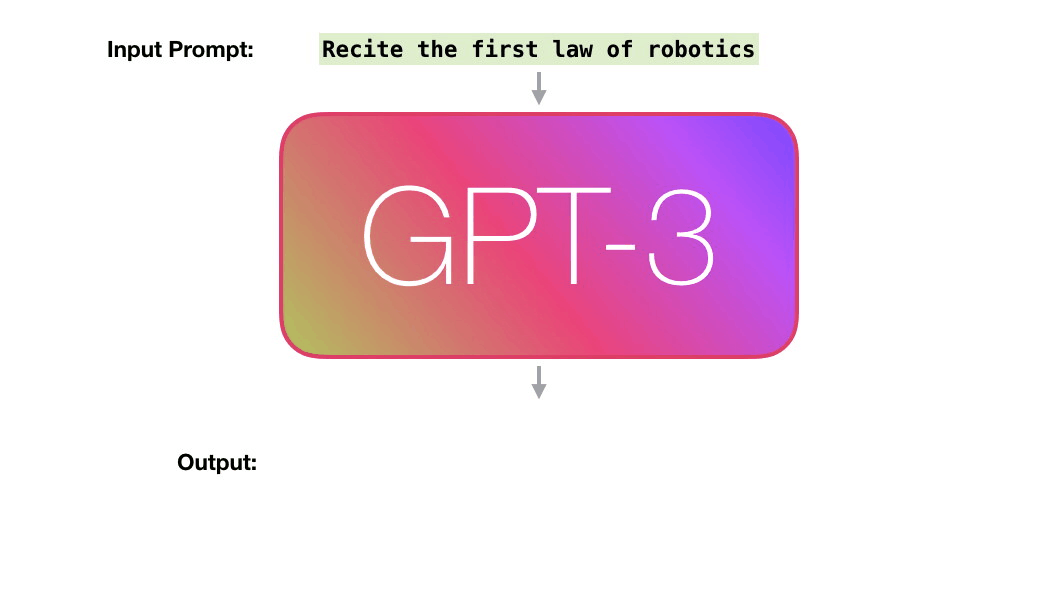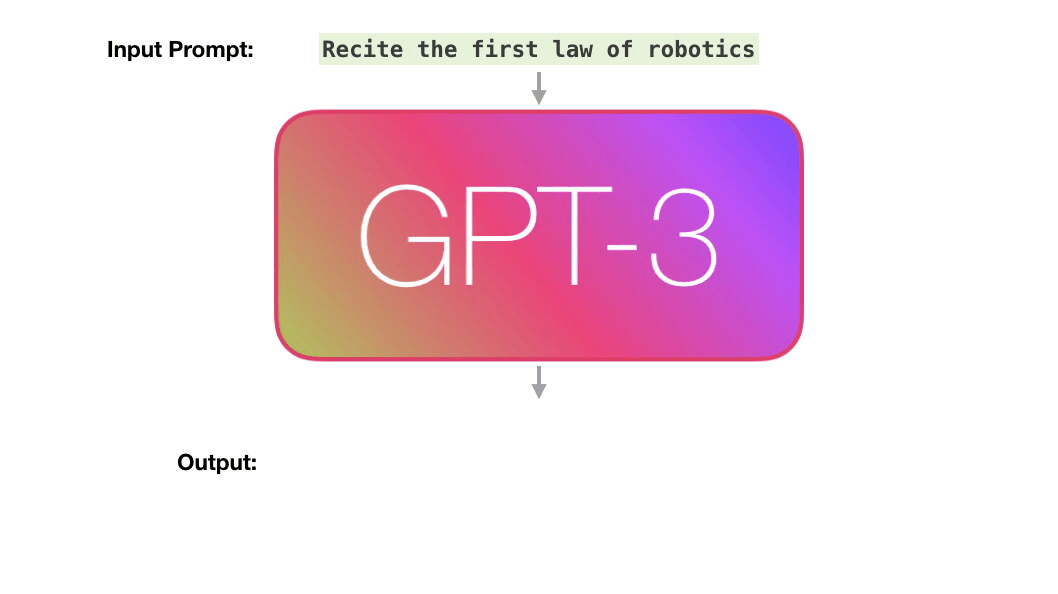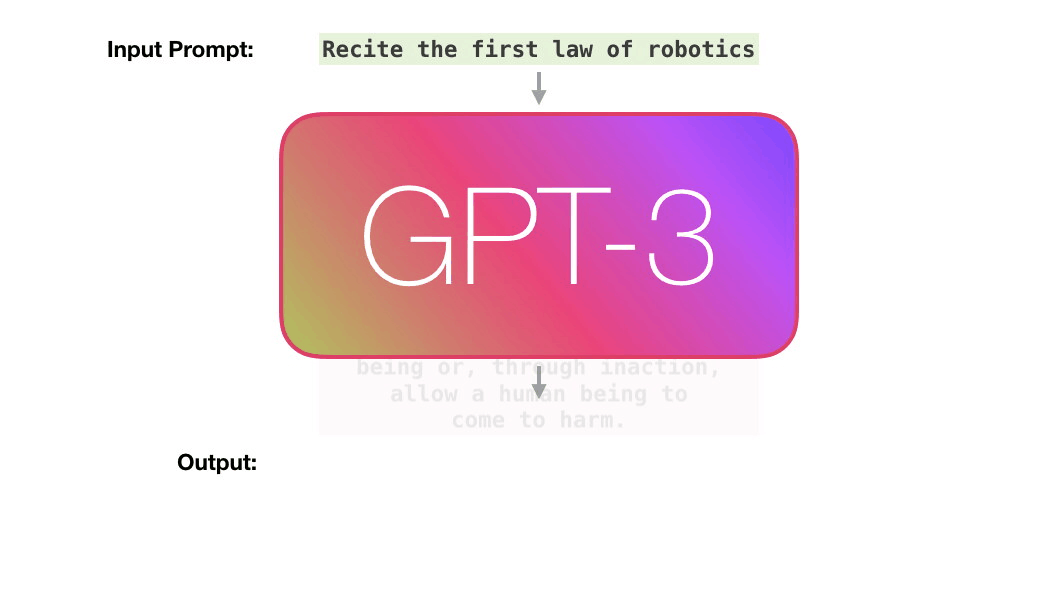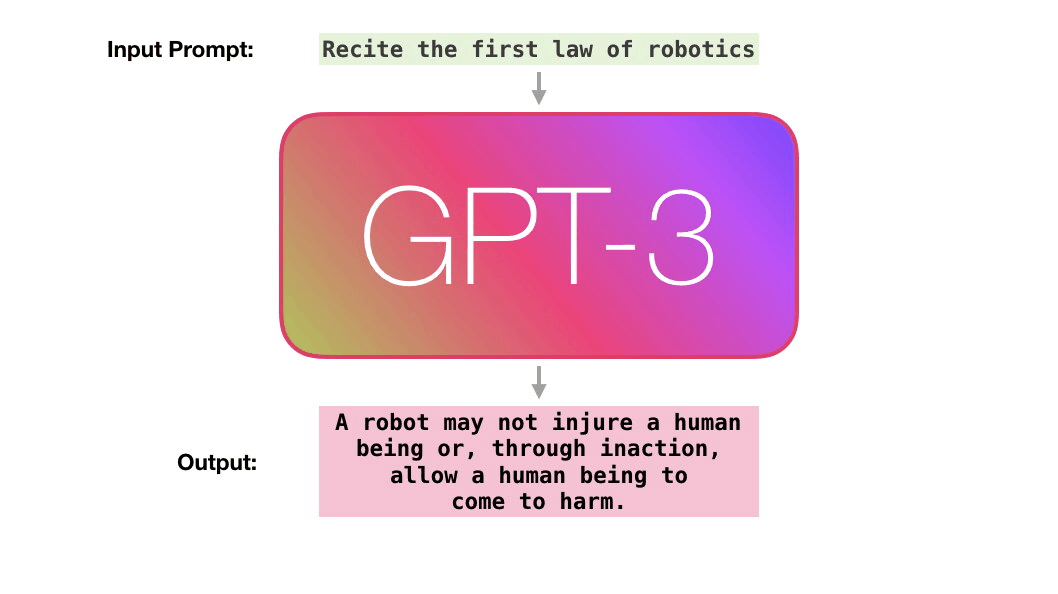
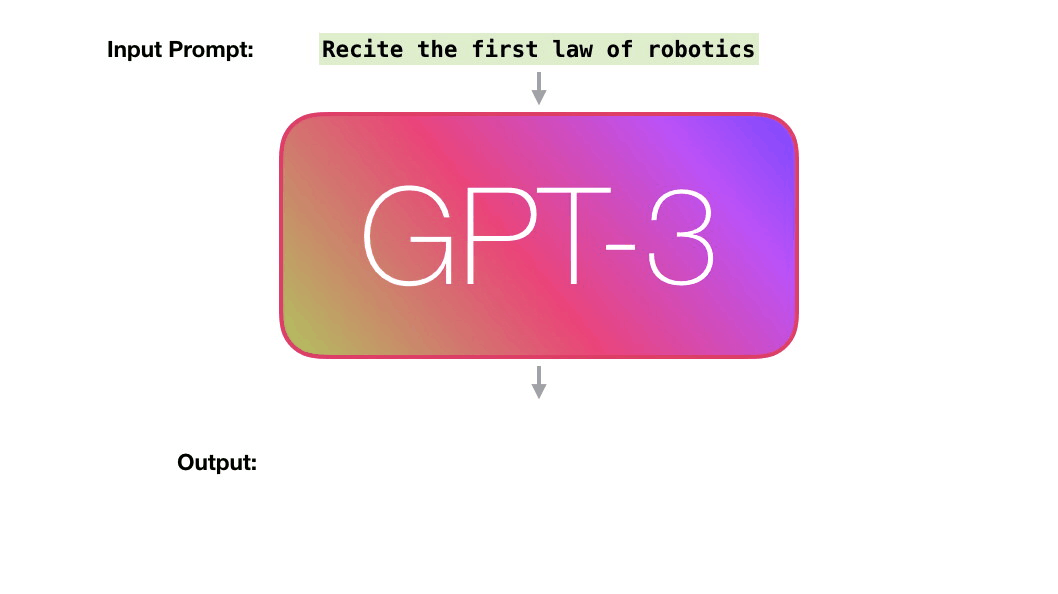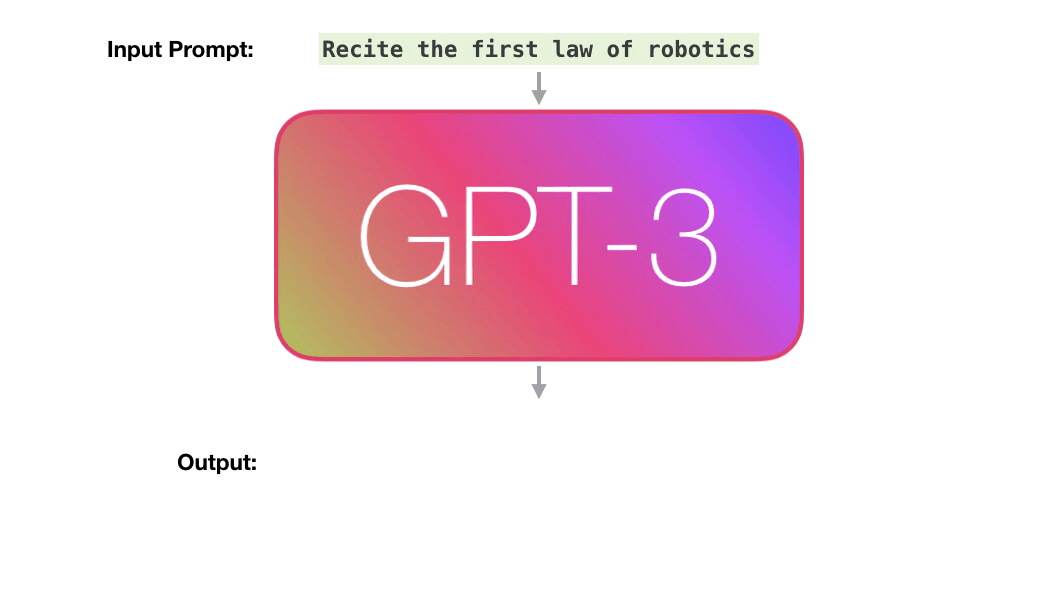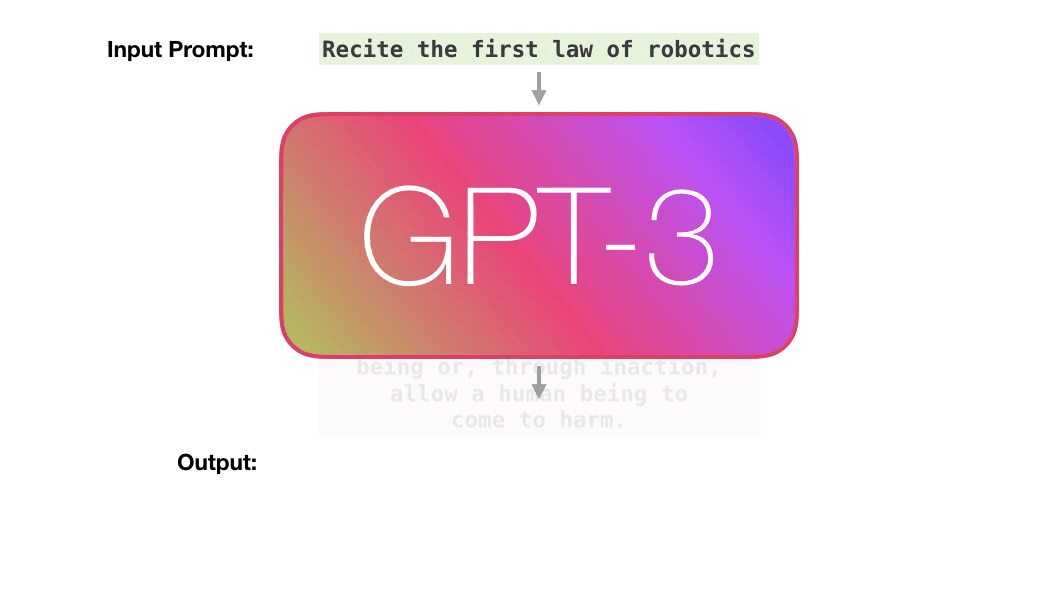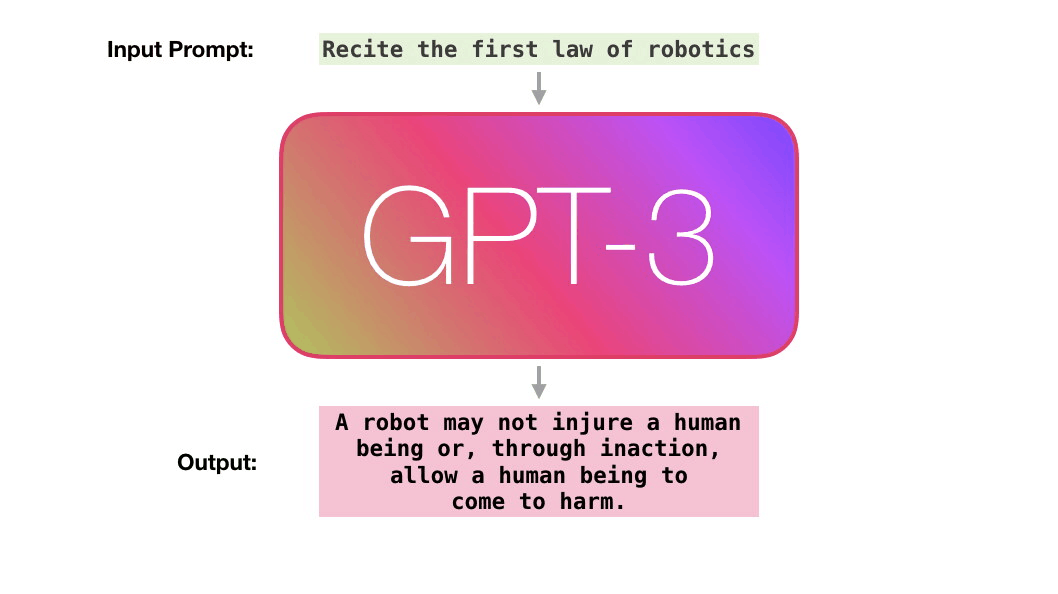
In December 2017, a group of researchers asked themselves, “Will Artificial Intelligence be writing most of the computer code?”. They estimated that this could happen by 2040. But we may already be seeing the start of that. AutoML by Google is an AI that can write computer code with a much higher rate of efficiency than the researchers who developed it. But this next AI is some steps ahead of that. Generative Pre-trained Transformer 3 or GPT-3 is a deep learning algorithm that produces human-like text. It’s a 3rd generation language prediction created by Open AI, a San Francisco based startup which was co-founded by Elon Musk. It was introduced on 28th May 2020 and is in beta testing since 11th June 2020.
Comparing GPT-3 to GPT-2 is like comparing apples to, well, raisins, because the model is about that much larger. While GPT-2 weighed in at a measly 1.542 billion parameters (with smaller release versions at 117, 345, and 762 million), the full-sized GPT-3 has 175 billion parameters. GPT-3 was also matched with a larger dataset for pre-training: 570GB of text compared to 40GB for GPT-2.
GPT-3 is the largest natural language processing (NLP) transformer released to date, eclipsing the previous record, Microsoft Research’s Turing-NLG at 17B parameters, by about 10 times. Unsurprisingly there has been plenty of excitement surrounding the model, and, given the plethora of GPT-3 demonstrations on Twitter and elsewhere, OpenAI has apparently been pretty accommodating in providing beta access to the new API. This has resulted in an explosion of demos: some good, some bad, all interesting. Some of these demos are now being touted as soon-to-be-released products, and in some cases may actually be useful. One thing’s for certain, NLP has come a long way from the days when naming guinea pigs or writing nonsensical sci-fi scripts were killer apps.
Ideally, OpenAI would have made GPT-3 available to the public. But we live in the era of commercial AI, and AI labs like OpenAI rely on the deep pockets of wealthy tech companies and VC firms to fund their research. This puts them under strain to create profitable businesses that can generate a return on investment and secure future funding.
In 2019, OpenAI switched from a non-profit organization to a for-profit company to cover the costs of their long marathon toward artificial general intelligence (AGI). Shortly after, Microsoft invested $1 billion in the company. In a blog post that announced the investment, OpenAI declared they would be commercializing some of their pre-AGI technologies.
So, it was not much of a surprise when, in June, the company announced that it would not release the architecture and pretrained model for GPT-3, but would instead make it available through a commercial API. Beta testers vetted and approved by OpenAI got free early access to GPT-3. But starting in October, the pricing plan will come into effect.
In the blog post where it declared the GPT-3 API, OpenAI stated three key reasons for not open-sourcing the deep learning model. The first was, obviously, to cover the costs of their ongoing research. Second, but equally important, is running GPT-3 requires vast compute resources that many companies don’t have. The third is to prevent misuse and harmful applications.
Based on this information, we know that to make GPT-3 profitable, OpenAI will need to break even on the costs of research and development, and also find a business model that turns in profits on the expenses of running the model.
The costs of training GPT-3:-
GPT-3 is a very large Transformer model, a neural network architecture that is especially good at processing and generating sequential data. It is composed of 96 layers and 175 billion parameters, the largest language model yet. To put that in perspective, Microsoft’s Turing-NLG, the previous record-holder, had 17 billion parameters, and GPT-3’s predecessor, GPT-2, was 1.5-billion-parameters strong.
Lambda Labs calculated the computing power required to train GPT-3 based on projections from GPT-2. According to the estimate, training the 175-billion-parameter neural network requires 3.114E23 FLOPS (floating-point operation), which would theoretically take 355 years on a V100 GPU server with 28 TFLOPS capacity and would cost $4.6 million at $1.5 per hour.
“Our calculation with a V100 GPU is extremely simplified,” Chuan Li, Lambda Lab’s Chief Science Officer, told me. “In practice you can’t train GPT-3 on a single GPU, but with a distributed system with many GPUs, like the one OpenAI used.”
Adding parallel graphics processors will cut down the time it takes to train the deep learning model. But the scaling is not perfect, and the device-to-device communication between the GPUs will add extra overhead. “So, in practice, it will take more than $4.6 million to finish the training cycle,” Li said.
It is worth noting is that specialized hardware, such as the supercomputer Microsoft built in collaboration with OpenAI’s talent, might prove to be more cost-efficient than parallel V100 clusters.
Cost of running GPT-3:-
Many research labs provide pre-trained versions of their models to save developers the pain and costs of training the neural networks. They would then only need to have a server or device that can load and run the model, which is much less compute-intensive than training it from scratch.
But in the case of GPT-3, the sheer size of the neural network makes it very difficult to run it. According to the OpenAI’s whitepaper, GPT-3 uses half-precision floating-point variables at 16 bits per parameter. This means the model would require at least 350 GB of VRAM just to load the model and run inference at a decent speed.
This is the equivalent of at least 11 Tesla V100 GPUs with 32 GB of memory each. At approximately $9,000 a piece, this would raise the costs of the GPU cluster to at least $99,000 plus several thousand dollars more for RAM, CPU, SSD drives, and power supply. A good baseline would be Nvidia’s DGX-1 server, which is specialized for deep learning training and inference. At around $130,000, DGX-1 is short on VRAM (8×16 GB), but has all the other components for a solid performance on GPT-3.
It would be safe to say the hardware costs of running GPT-3 would be between $100,000 and $150,000 without factoring in other costs (electricity, cooling, backup, etc.).
Potential of GPT-3:-
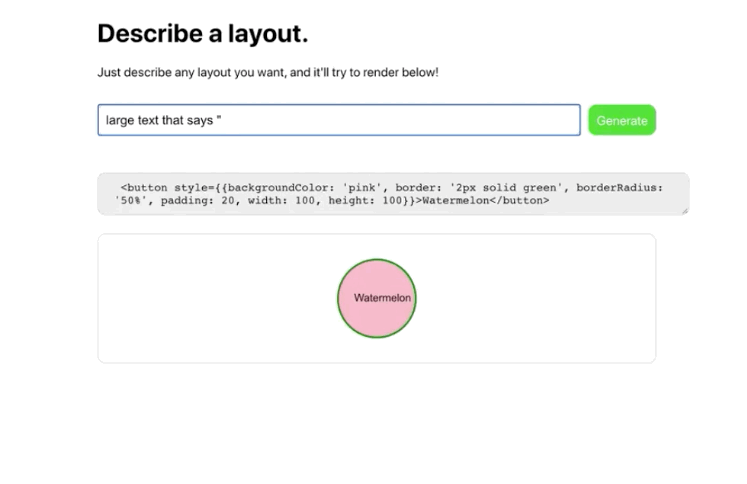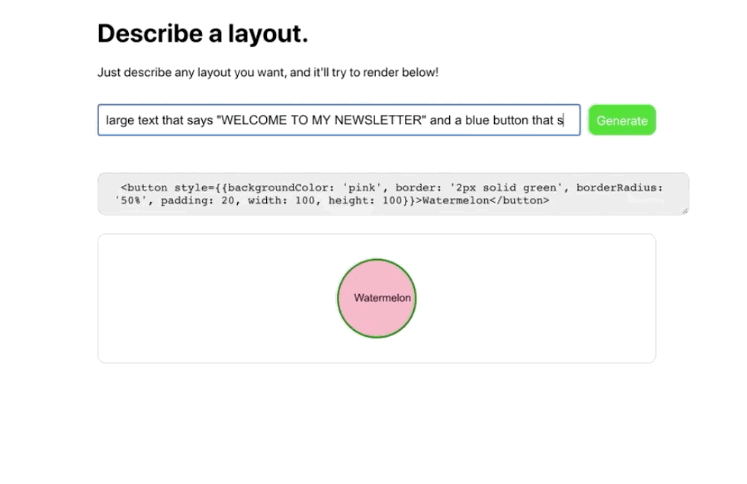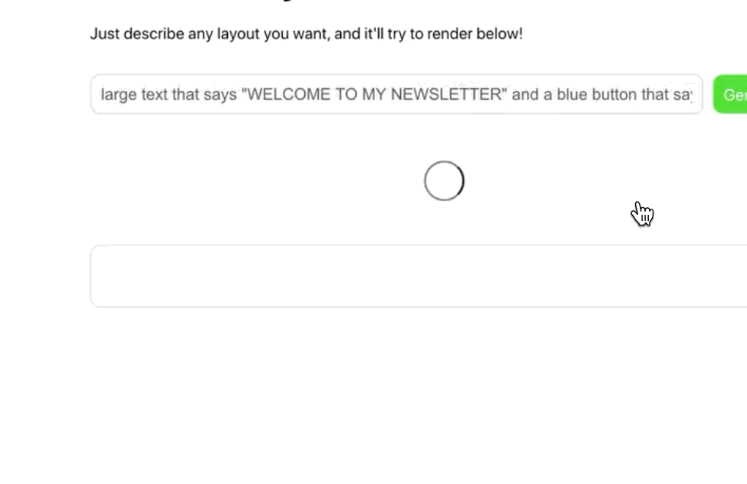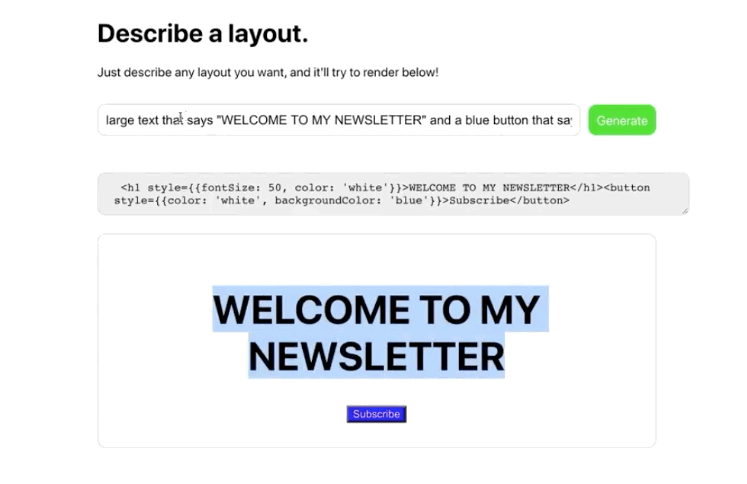
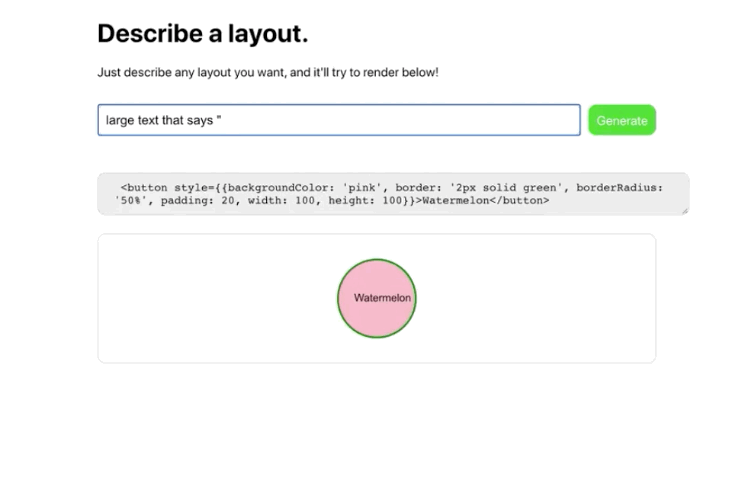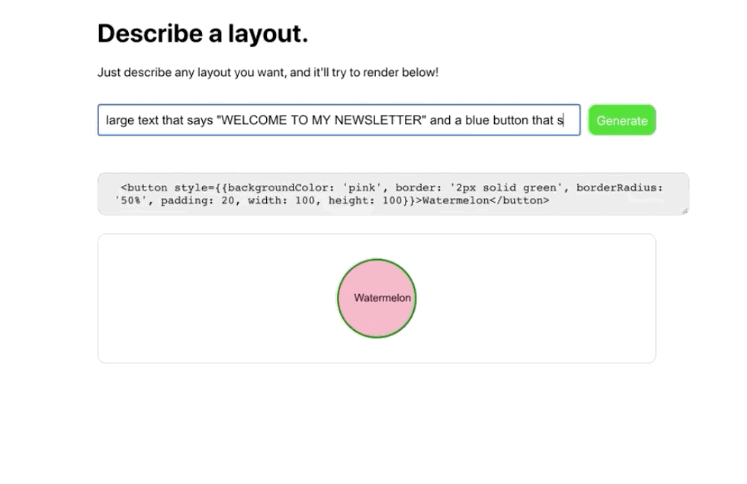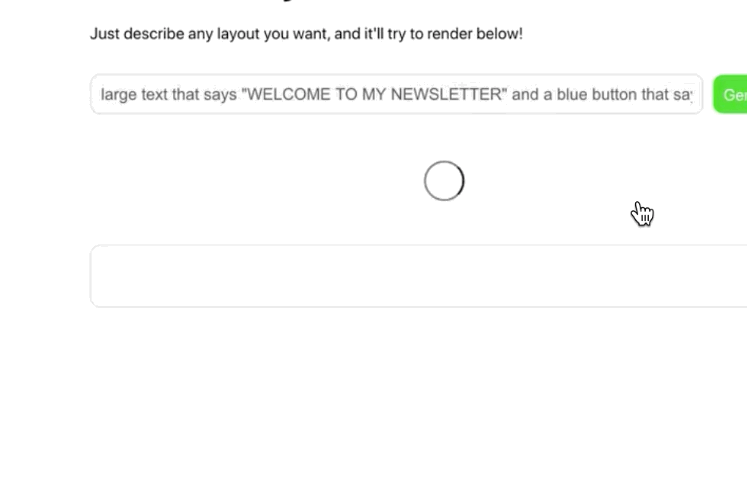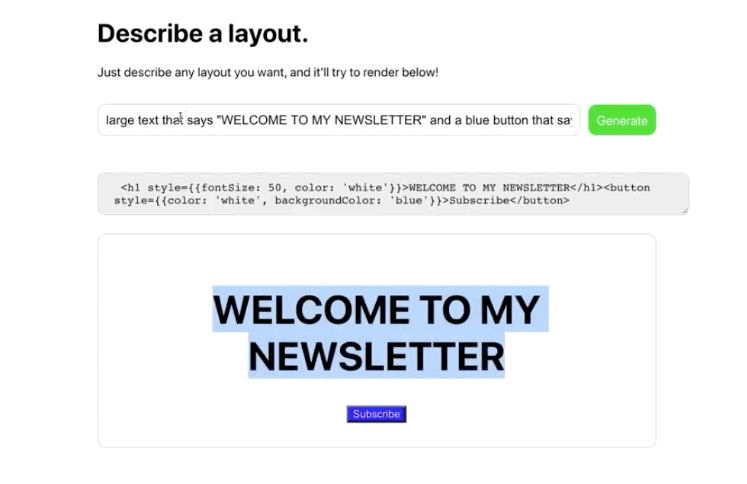
OpenAI announced that users could request access to its user-friendly GPT-3 API a “machine learning toolset” to help OpenAI “explore the strengths and limits” of this new technology. The invitation described how this API had a general-purpose “text in, text out” interface that can complete almost “any English language task”, instead of the usual single use-case.
GPT-3 program is better than any other program at producing high quality and it is difficult to distinguish between that text and the text written by a human being. For this, GPT-3 uses the concept of the conditional probability of text. GPT-3 can write a code in any language just when given a text description. It can also create a mock-up website by just copying and pasting a URL with a description.
Almost certainly the most thorough and visible investigation into GPT-3 for creative writing comes from Gwern Branwen at gwern.net. Having followed the NLP progress at OpenAI over the years, Gwern describes GPT-1 as “adorable,” GPT-2 as “impressive,” and GPT-3 as “scary” in their varying capabilities to mimic human language and style in text. Gwern has spent a substantial amount of time exploring the capabilities of GPT-3 and its predecessors, and the resulting musings on the current generation of GPT model and what might be holding it back are worth a read.
The OpenAI API does not currently facilitate a way of directly fine-tuning or training the GPT-3 model for specific tasks. Gwern argues, however, that the ability of GPT-3 to mimic writing styles and generate different types of output merely from a dialogue-like interaction with the experimenter amounts to a kind of emergent meta-learning. This wasn’t present in GPT-2, and Gwern posits the transformer attention mechanism as the means to facilitate this capability.
It can even explain the code back to you in plain English and can suggest improvements. This type of technology can simplify work and amplify productivity for a lot of small to medium and even large-scale business firms.
It may be proven useful to many companies and has a great potential in automating tasks. This AI can write anything. For example,
- We can input poems of a particular poet, and it will produce a new poem with the same rhythm and genre.
- It can also write news articles.
- It can read an article and answer questions about that information.
- It can also summarize any complicated text in simple terms.
- It can also finish your unfinished essays.
- It can generate pictures from a text description.
Risks associated with GPT-3


GPT-3 has all these benefits but this technology also comes with some demerits. 31 OpenAI researchers and engineers have warned of GPT-3’s potentially harmful consequences. They have called for research to mitigate the risk. They have listed some negative effects like,
- Misinformation
- Fake news articles
- Social engineering
- Spam
- Phishing
- Fraudulent academic essay writing
The last one will be the most common misuse of GPT-3. This tool will aid a lot of students into bluffing their way through colleges and universities. In August 2020, a college student Liam Porr was caught using GPT-3 to write fake blog entries. He fooled his subscribers into believing that the text was written by a human and he did it with ease, which is honestly the scary part.




